எனது ஸ்கேன் செய்யப்பட்ட PDF கோப்பில் உள்ள உரையை நான் அடைவுகூறு ஆக்கவும், வகையாக்கவும் முடியவில்லை.
தீர்க்கப்பட்டது OCR PDF
சிக்கல்
என் வேலையில், எனக்கு ஒரு பிரச்சினை ஏற்படுகிறது, அதாவது, எனது ஸ்கேன் செய்த PDF ஆவணங்களின் உரையை மாற்றலாமல் அல்லது தேட முடியவில்லை, இது வேலை செயல்முறையை குறிக்கிட்டது. மேலும், ஆவணங்களில் உள்ள தகவல்களை அடையாளமிடுவது மற்றும் வகைப்படுத்தவும் முடியாது, இது தகவல்களை காண்பதில் விசேட குழப்பத்தை ஏற்படுத்துகிறது. மேலும், ஸ்கேன் செய்த பிறகு ஏற்பட்ட பிழைகளை சரி செய்வது முடியாது. உரை அடையாளமிடல் மற்றும் மாற்றத்திக்கான வாய்ப்புகள் கூட இல்லை. ஆவணங்களின் அதிக அளவில் இது பிரச்சனைகளை ஏற்படுத்துகிறது மற்றும் தயாரிப்பு மற்றும் திறனுலக்கை பாதிக்கிறது.
திரைப்படங்கள்
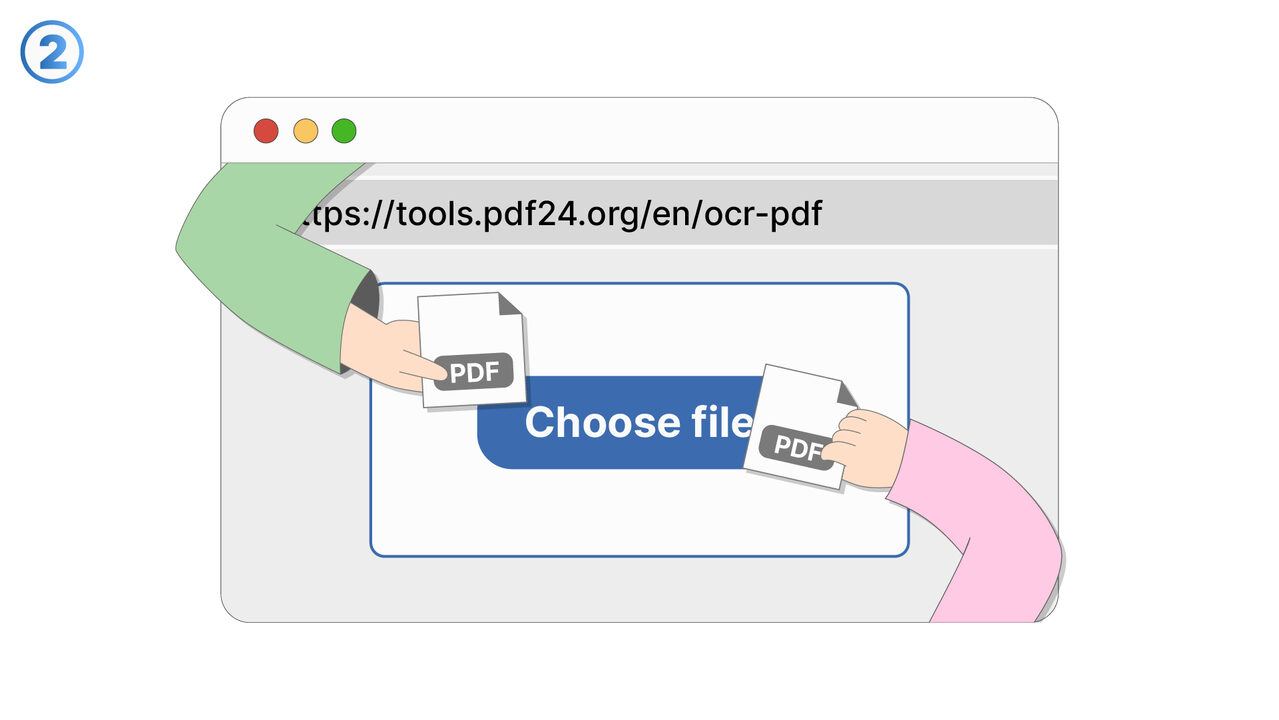
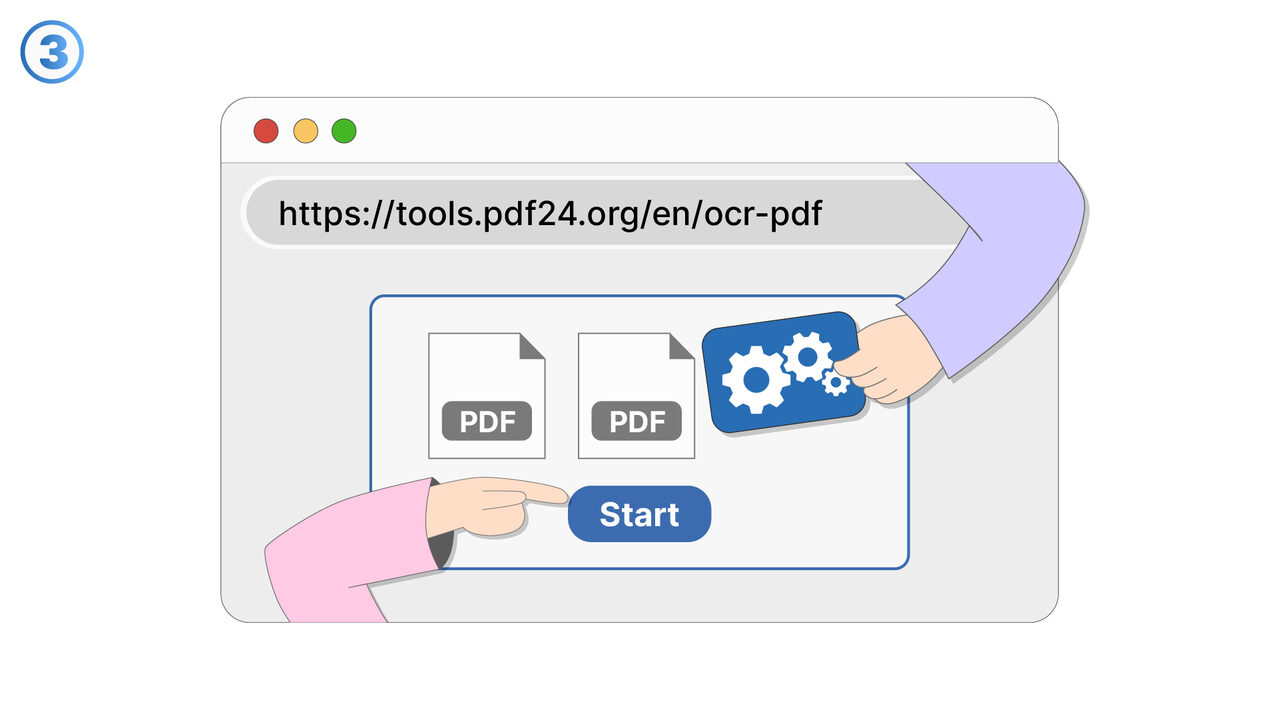
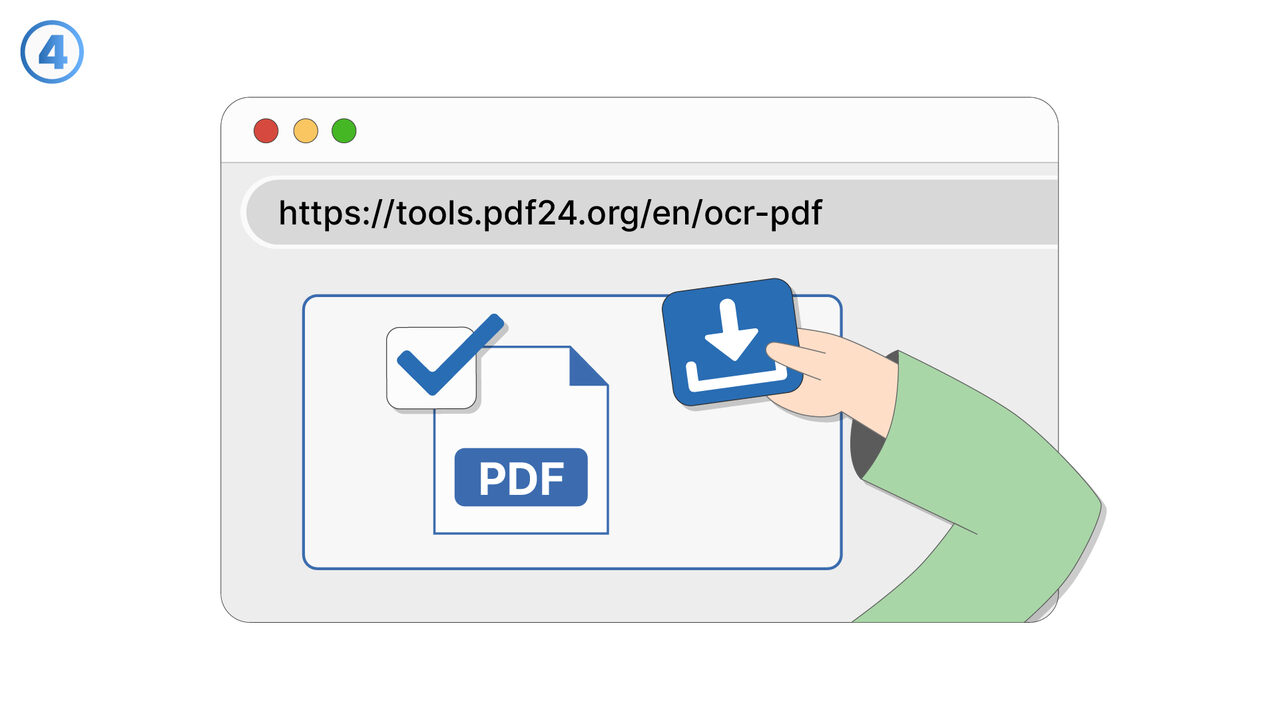
தீர்வு
OCR PDF கருவி மேலே குறிப்பிட்ட சவால்களுக்கு தனிப்பட்ட தீர்வு. அது வெளிப்படையான அச்சுகலைத் தெரியப்படுத்தும் தொழில்நுட்பத்தைப் பயன்படுத்துவதன் மூலம், ஸ்கேன் செய்த பிடிஎப் ஆவணங்களிலிருந்து உரையை எடுக்கும் மற்றும் திருத்தப்பட்ட உரையாக மாற்றும். இதனால் விசாரணைக்குடன் தகவல்களை அட்டவணைப்படுத்துவது முடியும், இது தகவல் நிர்வாகம் மற்றும் மேம்படுத்தப்பட்ட கண்டறிதல் நிச்சயப்படுத்துகின்றது. ஸ்கேன் செய்ய முடிந்து உருவான தவறுகளை எளிதில் திருத்த முடியும். என்பதைக் கையேழுத்து ஆவணங்கள் OCR PDF கருவிக்கு பிரச்சனையல்ல, அவ்வளவுக்கு கையேழுத்து தெளிவாக இருந்தால். தட்டிய, கையேழுத்து, அல்லது அச்சிடப்பட்ட உரை என்ன இருந்தாலும் - OCR PDF கருவி மிகவு உவமையுடன் அதைக் கணக்கிடுகிறது மற்றும் மீண்டும் வேலை செய்கிறது. பெரும்பாலும் ஆவண அளவுகளில், இந்த கருவி உயர்ந்த தயாரிப்பு மற்றும் திறன் அதிகரிப்புக்கு மிகுந்த பங்களிக்கும்.
வெளி ஆதாரம்
https://tools.pdf24.org/en/ocr-pdf
பின்வரும் சிக்கல்களுக்கான தீர்வாக இந்தக் கருவியைப் பயன்படுத்துங்கள்
- எனது PDF கோப்பில் உள்ள உரையை நான் திருத்த முடியவில்லை மற்றும் அதற்கான தீர்வை வேண்டுகிறேன்.
- நான் பழைய காகித ஆவணங்களை மின்னோட்டமாக்குவதில் பிரச்சினைகளை எதிர்கொள்கிறேன்.
- எனது PDF கோப்பின் உள்ளடக்கத்தை நான் தேட முடியவில்லை, மேலும் உரைப் படித்தலுக்கான கருவி தேவைப்படுகின்றது.
- நான் ஒரு ஸ்கேன்சீட்டுக்குள் உள்ள உரையை நகலெடுக்கும் போது பிரச்சினைக்குள்ளாகிவிட்டேன்.
- நான் உடற்பொருட்களிலிருந்து உரையை எடுத்துவிடுவதற்கும் மின்னோத்துவதைக்கும் பிரச்சினைகளுக்குள்ளாகிவிட்டேன்.
- எனது ஸ்கேன் செய்த PDF ஆவணங்களில் பிழைகளை நான் சரிசெய்ய முடியவில்லை.
- எனது உடல்நிலையான ஆவணங்களில் இருந்து உரையை எடுக்கும் மற்றும் நிர்வகிக்கும் விஷயத்தில் நான் பிரச்சனைகளை எதிர்கொள்கின்றேன்.
- நான் உடைந்த ஆவணங்களிலிருந்து உரையை எடுக்க மற்றும் அவற்றை மின்னஞ்சலில் பகிர்ந்து கொள்வதில் சவால்களை அனுபவிக்கின்றேன்.
- நான் படத்தைக் காட்டிய PDFகளின் உள்ளடக்கத்தை மாற்றியமைக்க முடியும் உள்ளடக்கமாக மாற்றுவதில் சிரமத்தை அனுபவிக்கின்றேன்.
சிறந்த தீர்வு தெரியுமா? எங்களுக்கு தெரியப்படுத்துங்கள்.
நாங்கள் இன்னும் உள்ளடக்காத சிக்கலை தீர்க்க உதவும் ஒரு கருவி அல்லது அணுகுமுறை தெரிந்தால், நாங்கள் அதை அறிய விரும்புகிறோம்.