నా PDF ఫైల్లో ఉన్న పాఠ్యాన్ని సవరించలేకపోతున్నాను మరియు దానికి పరిష్కారం కావాలని అనుకుంటున్నాను.
Solved by OCR PDF
The Problem
ప్రముఖ సవాలు పిడిఎఫ్ ఫైల్లో ఉన్న పాఠ్యాన్ని సవరించాలసినవి ప్రాప్యత కానివి. ఇది డిజిటలైజేషన్ చెందిన పాత పత్రాలు, టైప్ చేసిన వాటిని, హస్తాఖరిత లేదా ముద్రించిన పాఠ్యాలపై ప్రభావముందు. ఇంకా, హస్తాఖరిత పరిమార్జన ద్వారా తప్పుడుగా ప్రదర్శించబడిన కొన్ని విషయాలను సరిచేయాల్సి ఉండొచ్చు. మరియు, పత్రంని శోధనీయమై మరియు ఇండెక్సబల్గా చేయే అవసరం కూడా ఉండొచ్చు, ఇది ప్రాధాన్యం చాలా విపణి పత్రాలు ఉండడంలో ఉపయోగపడుతుంది. ఇది దస్త్రుపరిచరణ యొక్క ప్రతిపాదకతను మరియు ప్రభావశీలతను మెరుగుపరచడానికి సహాయపడే నమ్మకమైన మరియు ఖచ్చితమైన పరిష్కరింపు అవసరంగా ఉన్నది.
Screenshots
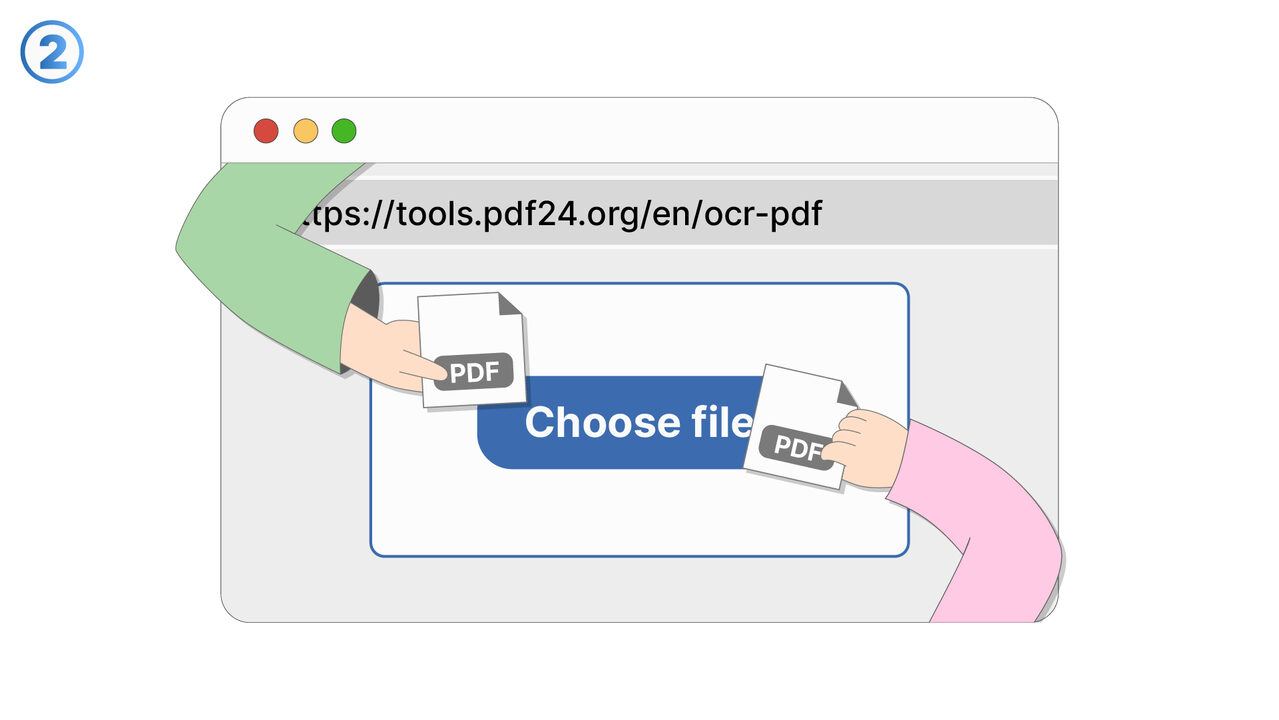
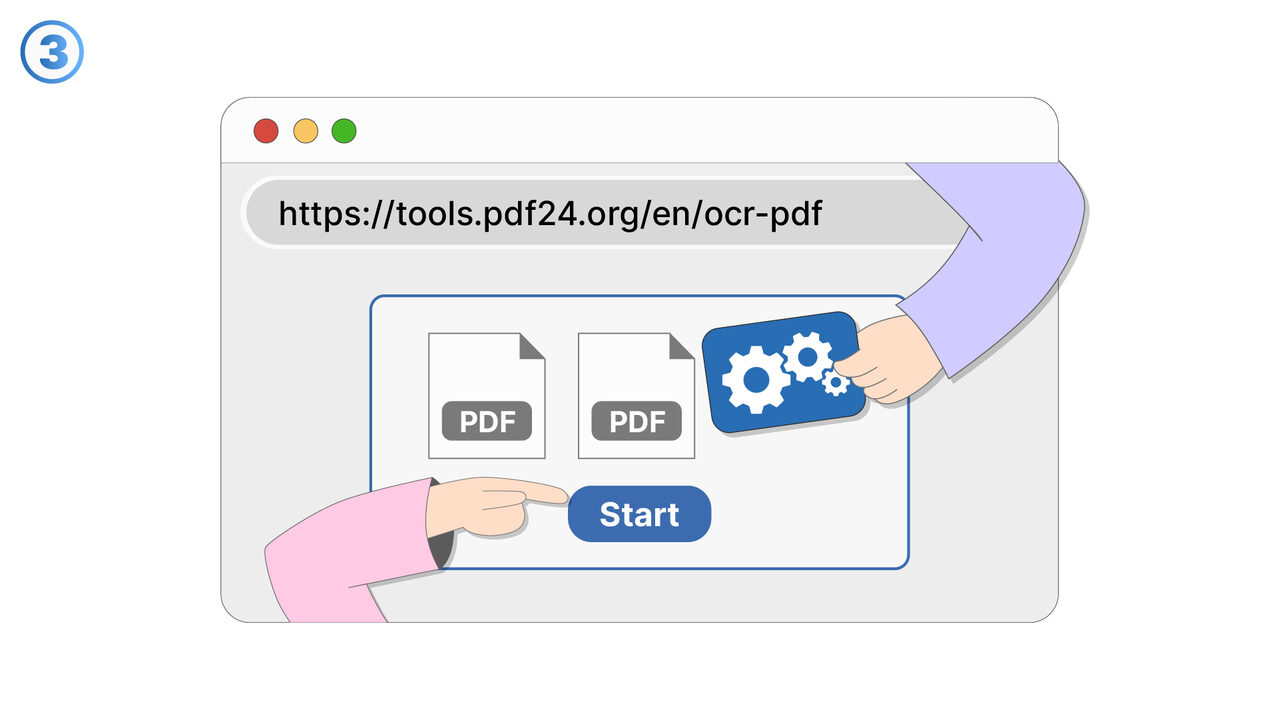
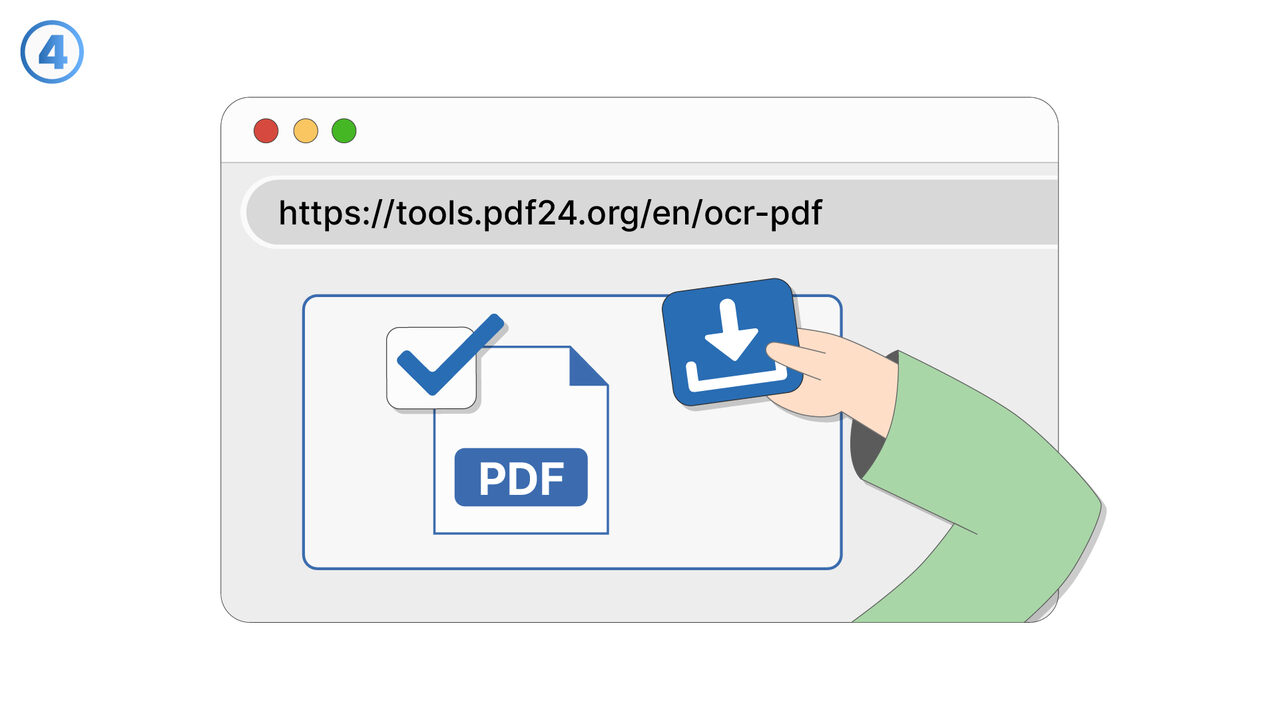
The Solution
OCR PDF టూల్ ఆప్టికల్ ఖరాకార గుర్తింపును ఉపయోగించి, ప్రాసెస్చేయని PDF ఫైళ్లలో నుండి పాఠ్యాన్ని ఎక్స్ట్రాక్ట్ చేయడానికి అమూల్య మదదును అందిస్తుంది. దీనిలో టక్స్ట్ యొక్క చిత్రాలను సవరించదగ్గ పాఠ్యానన్ని మారుస్తుంది, ఇది పాత పత్రాల డిజిటిజేషన్ కోసం ఆదర్శంగా సరిపోతుంది. స్కేన్ ప్రక్రియలో ఇది టైప్ చేయబడిన పాఠ్యాన్ని, హస్తలిఖిత మరియు ముద్రిత పాఠ్యాన్ని గుర్తిస్తుంది మరియు మారుస్తుంది. ఫలితం ఒక శోధానీయ మరియు సూచీకరణ ఉన్న PDF, డాక్యుమెంట్లు పరిచాలన చేసేందుకు ఏకాంగి మహత్వం ఉంది. ఇంకా ఇది హస్తాక్షర ప్రక్రియాద్వారా ఉత్పన్నయైన తప్పు ప్రాతిపాదనలను సరిచేయడానికి అనుమతిస్తుంది. స్పష్టమైన హస్తలిఖితానికి తగువైన జాగ్రత్తతో ఉపయోగించడం ద్వారా, OCR PDF టూల్ గొప్ప యథార్థతను హామీగా ఇస్తుంది మరియు డాక్యుమెంట్ నిర్వహణ యొక్క ప్రయోగీతని మరియు ప్రభావాన్ని పెంచేందుకు ప్రధానమైన పాత్రం ఆడుతుంది.
External Resource
https://tools.pdf24.org/en/ocr-pdf
Use this tool as a solution to the following problems
- నాకు పాత కాగిత పత్రాలను డిజిటల్ గా మార్చడంలో సమస్యలు ఉన్నాయి.
- నా పిడిఎఫ్ ఫైల్లో ఉన్న విషయాన్ని నేను శోధించలేకపోతున్నాను మరియు టెక్స్ట్ గుర్తింపు సాధనాన్ని అవసరం చెందుతున్నాను.
- నేను స్కాన్ చేయబడిన డాక్యుమెంట్ నుండి పాఠ్యాన్ని కాపీ చేయడంలో సమస్యలు ఎదురవుతున్నాను.
- నాకు భౌతిక పత్రాల నుండి పాఠ్యాన్ని ఎగుమతి చేసి మరియు డిజిటలైజేషన్ చేయడంలో సమస్యలు ఉన్నాయి.
- నా స్కాన్ చేసిన PDF పత్రాల్లో లోపాలను సరిచేయలేకపోతున్నాను.
- నా శారీరిక పత్రాల నుండి పాఠ్యాన్ని తీసివెళ్ళడానికి మరియు నిర్వహించడానికి నాకు సమస్యలు ఉన్నాయి.
- నాకు భౌతిక పత్రాల నుండి పాఠ్యాన్ని ఎక్స్ట్రాక్ట్ చేయడం మరియు దాన్ని డిజిటల్గా పంచుకోవడంలో సవాలులు ఉన్నాయి.
- నా స్కాన్ చేసిన PDF లో ఉన్న పాఠాన్ని నేను సూచించలేకపోతున్నాను మరియు వర్గీకరించలేకపోతున్నాను.
- నాకు బిల్డ్ డర్గస్టెల్లెన్ PDFల్లోని పాఠ్యాన్ని ఎడిటబుల్ టెక్స్ట్గా మారించడంలో కష్టపడుతున్నాను.
Know a better solution? Let us know.
If you know of a tool or approach that could help people solve a problem we haven't covered yet, we'd love to hear about it.