Problém
Máte naskenovaný dokument, ze kterého chcete extrahovat určité textové informace. Kopírování textu se však stává problematické vzhledem k tomu, že naskenovaný dokument je v podstatě obrázek. Komplikací navíc je, že byste rádi měli textové informace v upravitelném formátu, abyste mohli opravit případné existující chyby. To se ukazuje jako obzvláště těžké, pokud byl text napsán ručně. Proto hledáte řešení, jak efektivně a přesně digitalizovat text z vašeho naskenovaného dokumentu a mít ho k dispozici v upravitelném formátu.
Snímky obrazovky
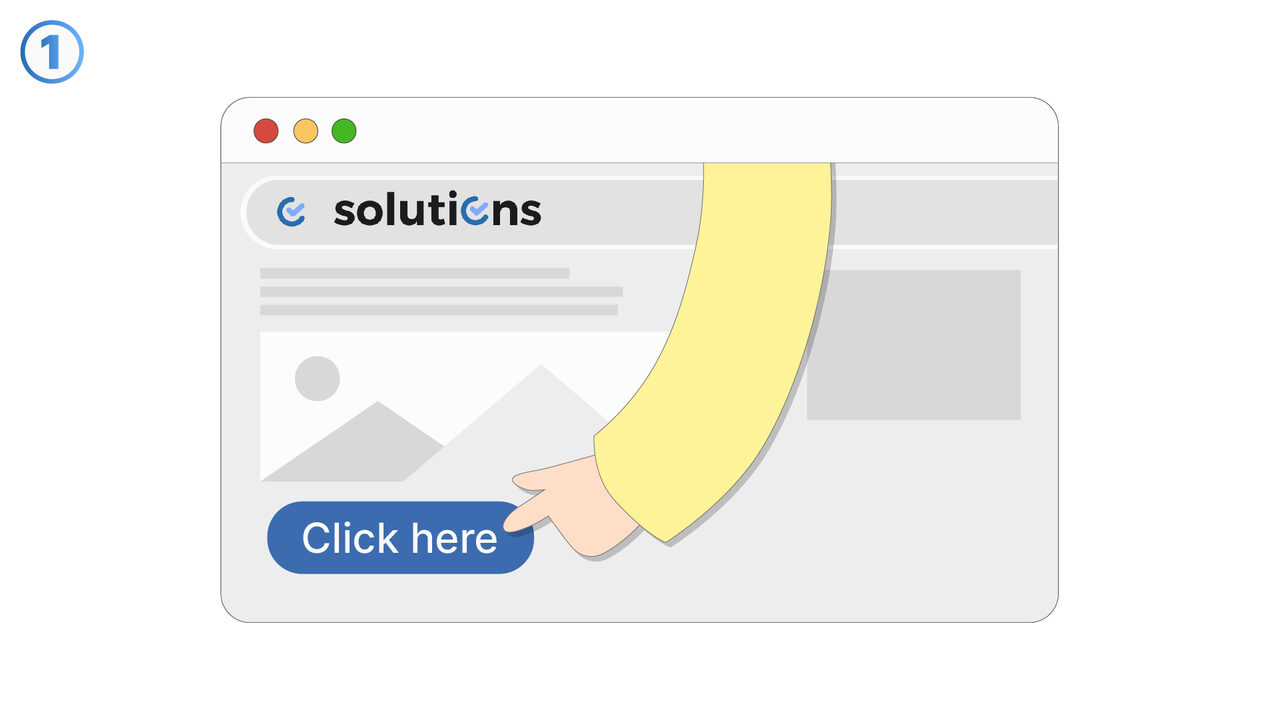
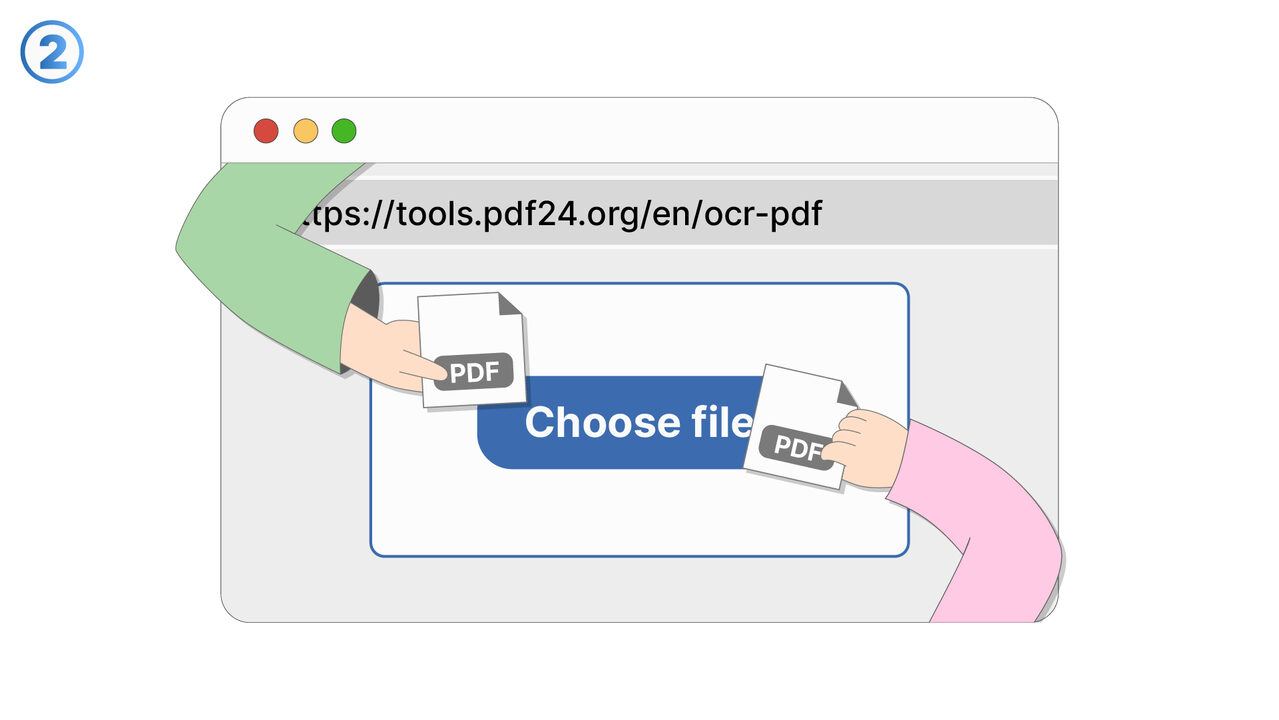
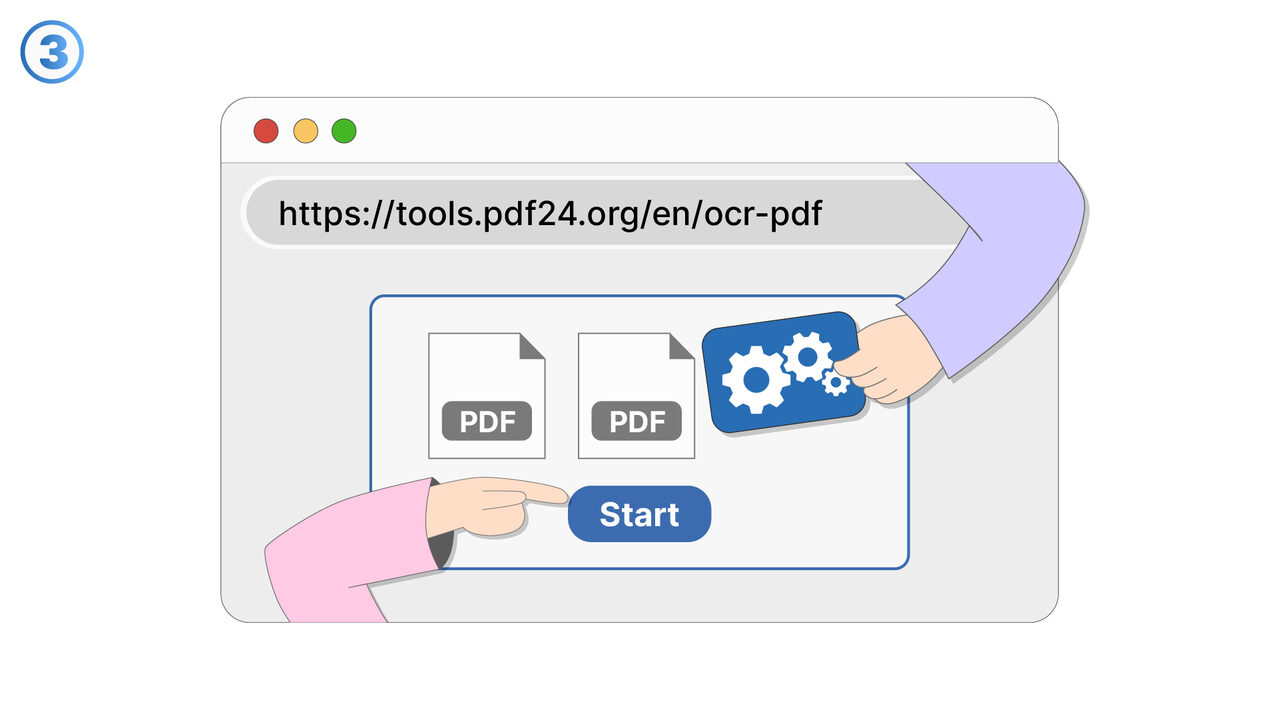
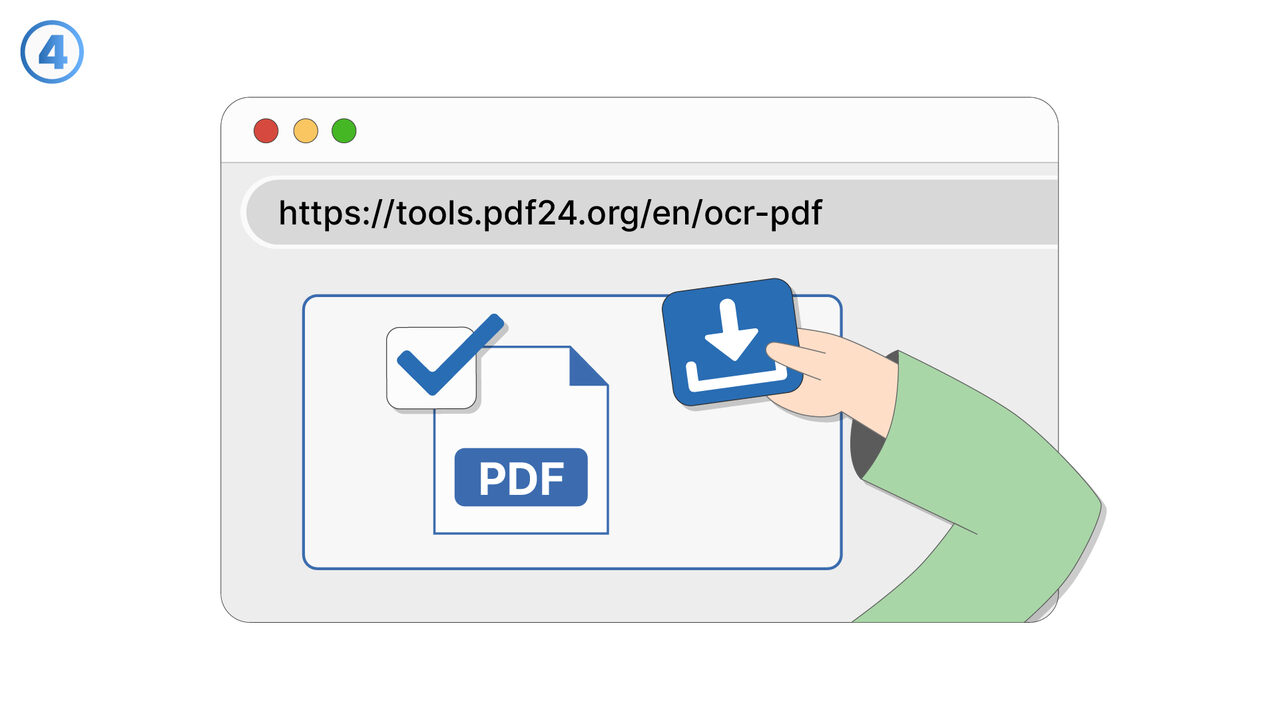
Řešení
OCR PDF nástroj je efektivním řešením vašeho problému. Využívá optické rozpoznávání znaků k vyextrahování textu z vašeho naskenovaného dokumentu, což je v podstatě obraz. Je schopen rozpoznat jak psaný, tak ručně psaný text a převést jej do digitální formy. Tím se text ve vašem PDF stává nejen čitelným, ale také prohledávatelným a indexovatelným. Díky tomuto nástroji můžete snadno opravovat chyby, protože text je v upravitelném formátu. I ručně psaný text není problém, pokud je písmo jasné a zřetelné. Použitím OCR PDF nástroje můžete značně zefektivnit a zpřehlednit digitalizaci a správu vašich dokumentů.
Externí zdroj
https://tools.pdf24.org/en/ocr-pdf
Použijte tento nástroj jako řešení následujících problémů
- Nemohu upravit text v mé PDF souboru a potřebuji na to řešení.
- Mám problémy s digitalizací starých papírových dokumentů.
- Nemohu prohledávat obsah v mé PDF souboru a potřebuji nástroj na rozpoznávání textu.
- Mám problémy s extrahováním a digitalizací textu z fyzických dokumentů.
- Nemohu opravit chyby v mých naskenovaných PDF dokumentech.
- Mám problémy s extrahováním a správou textu z mých fyzických dokumentů.
- Mám potíže s extrahováním textu z fyzických dokumentů a jejich digitálním sdílením.
- Nemohu indexovat a kategorizovat text v mé naskenované PDF.
- Mám potíže s převodem textu z PDF zobrazovaných jako obrázky na upravitelný text.
Znáte lepší řešení? Dejte nám vědět.
Pokud znáte nástroj nebo postup, který by mohl pomoci vyřešit problém, který jsme dosud nepokryli, rádi to uslyšíme.